序文 古くて新しい学術情報XMLの課題と展望
林 和弘
本書は論文を中心とした学術情報を、いかに機械に、今ではAIに読ませるかについて、日本の印刷会社を中心とした関係者がどのように取り組んでいるか、その奮闘ぶりをまとめた書である。序文に代えてその背景を追ってみたい。
まず、近代の科学研究は、“Publish or Perish(出版しないなら研究をやめなさい)”という表現で表されるように、その研究成果を研究論文ないしは書籍などの形で出版して発展してきた。特に理工医学系においては、研究論文の蓄積によって研究が発展し、“on the shoulders of giants(巨人の肩の上に乗る)”という言葉に象徴されるように、論文の蓄積によって知が体系化されてきた。そして、査読がその質の保証の大きな役割を果たしてきた。また、この知の蓄積を支える学術雑誌の仕組み(学術情報流通)と、それを前提とした研究者の振る舞いが研究者の評判や昇進に繋がり、研究費の獲得にも連動し、一種のエコシステムを構築し進化させてきた。この学術情報流通エコシステムは、現在インターネットの浸透によって、紙のジャーナルを電子化し、その関連サービスの開発も加わって大きく進化してきた。
このジャーナルの電子化は、その当初から元の文書のデータベース化の取り組みと共に進んできたが、2000年代に入ると、大手商業出版社や大手学会出版者を中心にXMLと呼ばれる構造化文書の運用がデファクトとなった。この運用の肝は、各論文について、構造化文書であり、要は機械が読みやすいXMLを先に作成し、それをワンソースとして、PDFやhtml等のマルチメディアに展開すること(マルチユース)である。この事自体は欧米の英文誌を中心に運用が成熟してきたが、筆者も日本化学会の英文誌でその体制を整え、一連の開発状況と考察を記録し啓発してきた。しかしながら、一部を除いて多くの日本の学術雑誌においては、XMLあるいはそれと同等の構造化文書を積極的に活用した学術雑誌出版が依然少ないのが現状である。むしろ今現在も事実上人が読みやすいPDFを先に作り、後から書誌XMLや全文html情報を作る労働集約作業を伴う方式が業界で広く受け入れられ、半ば安定運用状態になっているとも言える。もちろん、これは、これまで学術情報流通市場として、経済的、人的を含む様々な条件下で時間をかけて最適化した結果でもある。しかし、結果的に時間も費用もかかり、かつ、論文本文とメタデータの整合性がとりづらくなる。
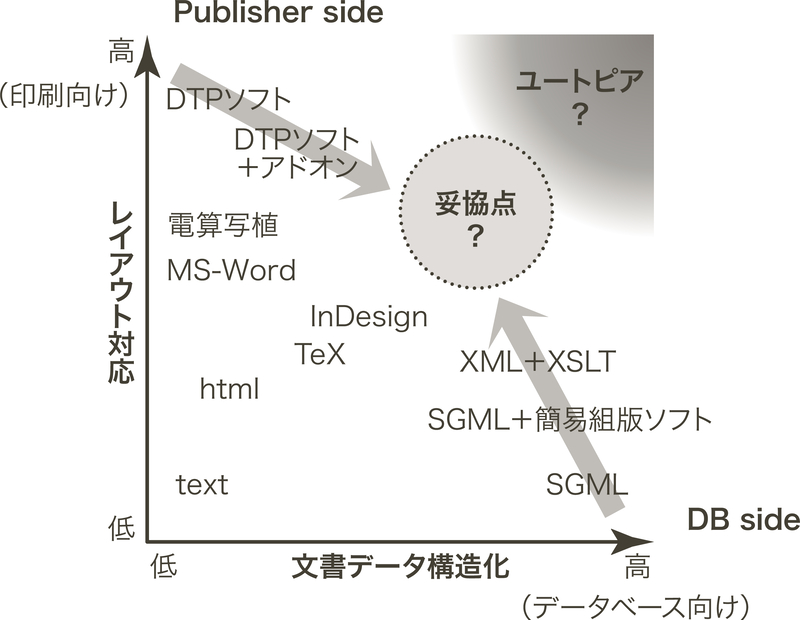
なぜ、このように遅れてしまったのか、その要因は色々考えられるが、一つの大きな要因として考えられるのは、紙面のレイアウトの自由度を日本は尊重する傾向にあるからだと思われる。2008年の論考1)において、紙面のレイアウトと、構造化文書の整合性のジレンマを論じた(図0.1)。要は、紙面のレイアウトにこだわると構造化文書が作りづらくなり、構造化文書のルールを厳密に適用すると、レイアウトの自由度が損なわれてしまう。この論文を執筆してから15年以上経っても、この構図は今も変わっていないようである。
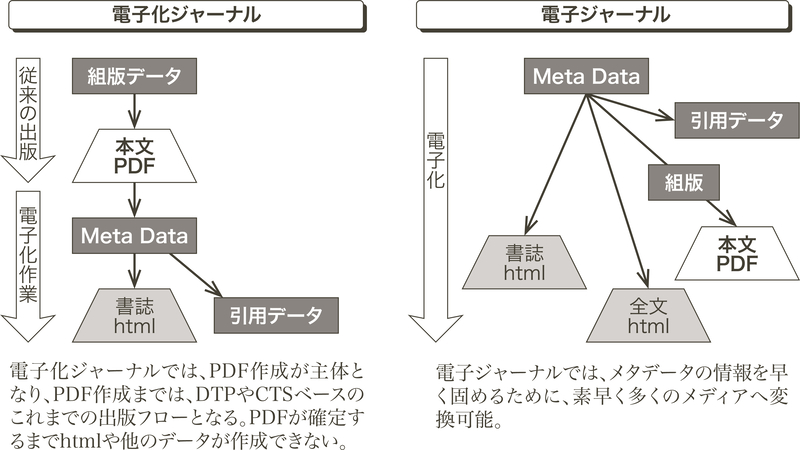
紙面というのはどこまで尊重されるべきなのか。それは読者に応じて、あるいは出版事情に応じて変わるものではあるが、例えば、総じて今の世代は紙よりもスマホの画面を見る時間が長くなってもいる。紙の持つ本質的な意義は変わることはないものの、結果的に今の社会の主体としてはデジタルベースの画面に最適化されたコンテンツがより重宝される時代になっているし、これからもその傾向は強くなるだろう。あるいは、学術情報の外側では、ウェブトゥーンのようにそもそも画面に特化したレイアウトもすでに社会に受け入れられ始めている。このような潮流を予見する形で、2013年に電子化ジャーナルと電子ジャーナルの違いを踏まえて、プリプレスのパラダイムシフトの重要性を論じた(図0.2、図0.3)2)。それはすなわち、人に読ませる印刷のためのプリプレスではなくて、デジタルサービスのためのプリプレスであり、さらに言い換えれば機械やAIに読ませるためのプリプレスが必要となる。
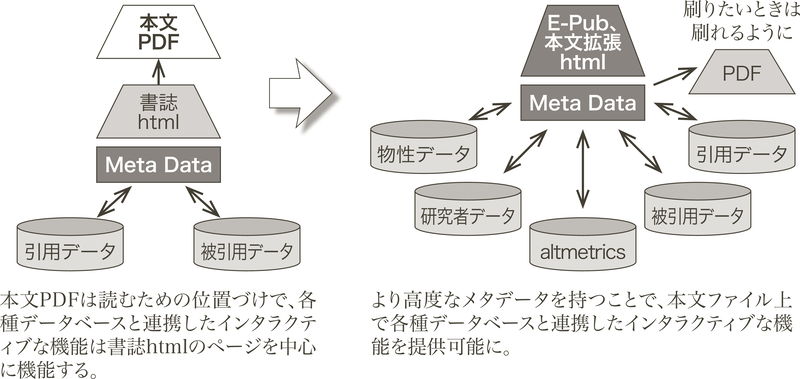
さらに、2020年代になると見方によっては破壊的とも言える新たな潮流が加わりつつある。データ科学の進展と生成AIの登場である。データ科学とAIの進展は様々な影響を与えているが、情報のタグ付けに関しても新たな議論を呼び込んだ。すなわち、タグを人手で付ける必要がないというものである。この議論はさらに2つに分けることができて、人手で付けていたタグをAIに助けてもらうという観点と、そもそも多量のデータに労働集約的にタグを付けるのは不可能になるので、その都度機械にタグ付けを任せることにして、それを前提としたほうが現実的であり、もはや人が関与する余地はないとするものである。
どうも、ここまでくると世の中が変わりすぎて、また、変わるポイントが多すぎて何をどうしたらよいか分かりにくくなってきたようだ。となると、どこかより確実なポイントに議論を戻すのが適当である。学術情報流通においては、オープンアクセスの潮流を踏まえながら、依然研究者にとって不可欠な学術論文を中心とした学術情報流通エコシステムを前提とすることが現実的であろう。そして、そのエコシステムにおいてXML化は前提条件となっている。XML化ができていないと、重要な抄録データベースの採録から外され、また、研究活動を可視化するツールから見えなくなるのである。では、具体的にどうやってXML化をすれば良いのだろうか。
ということで、本書の役割が俄然大きくなってくる。本書では、労働集約作業をいとわない力技の手法から、欧米に引けをとらないXMLファーストと自動組版の取り組み、あるいは、フォーマッターを積極的に活用する取り組みに加え、日本の組版において現在主流となっているInDesignを用いた取り組みなどが紹介されている。重要な点はこれらが、必ず数年以上の実績を伴っており、各事業者が積み上げたノウハウがあることである。そして、その他にも、学術XMLの標準であるJATSの誕生の経緯と文法や、J-STAGEの全文XML作成ツールの解説、AIを活用したXML変換の展望なども紹介されている。この本を手に取られてこの序章を読まれている方は、おそらく何かしらの学術誌に関わられていて、XML化に興味を持たれていることが強く推察される。本書の多様なXML化の手段を自身の状況に当てはめていただき、できる限り負担感を抑えつつ、効率よくあるいは正しく機械やAIに読ませることによって、世界に広く自身の学術誌の情報を届け、あるいはより高度なサービスを提供できるようになる一助となれば幸いである。
2024年12月